Working with Datasets
Datasets are the foundation of how Ask Monty works. Every time you ask a question, Monty creates focused datasets of feedback that are then used to generate your answer.What is a Dataset?
A dataset is a filtered collection of feedback snippets that match specific criteria. Think of it as a saved search tailored to your question. Example: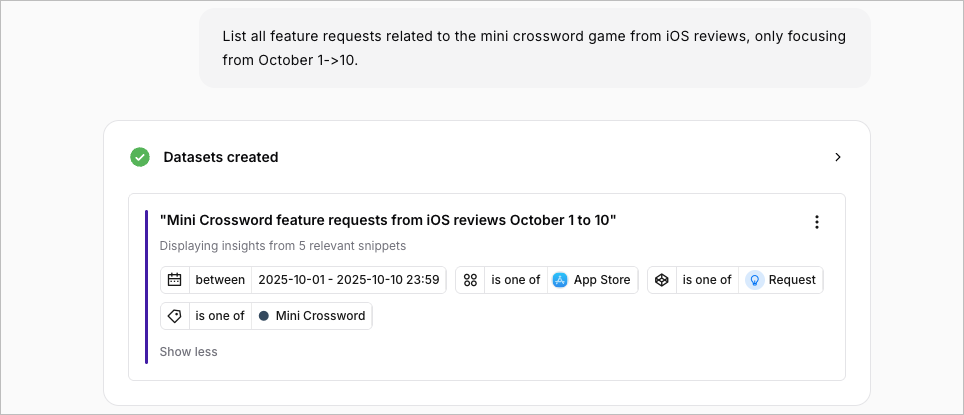
Dataset Components
Each dataset card displays a descriptive title (like “Checkout bugs • Last 60 days”), the total snippet count, and creation date. Below that, you’ll see all applied filters: time ranges, sources, categories, projects, tags, sentiment, text keywords, metadata fields, and customer segments. This transparency lets you verify that Monty understood your question correctly. Key actions are available on every dataset: you can export everything to CSV for external analysis, create a custom report around that specific dataset, or view the actual feedback snippets. If the filters aren’t quite right, rephrase your question to create a new dataset with better constraints.Dataset Types
Monty creates different dataset types depending on what you’re asking about. Feedback datasets are the most common, pulling from your standard product feedback across app stores, email, chat platforms like Intercom or Zendesk, reviews, and custom sources. These appear whenever you ask about customer complaints, bugs, feature requests, or general feedback topics. Survey datasets load when you ask about NPS scores, CSAT results, or custom survey responses. They include both quantitative scores and open-ended text responses, letting you analyze ratings alongside qualitative feedback.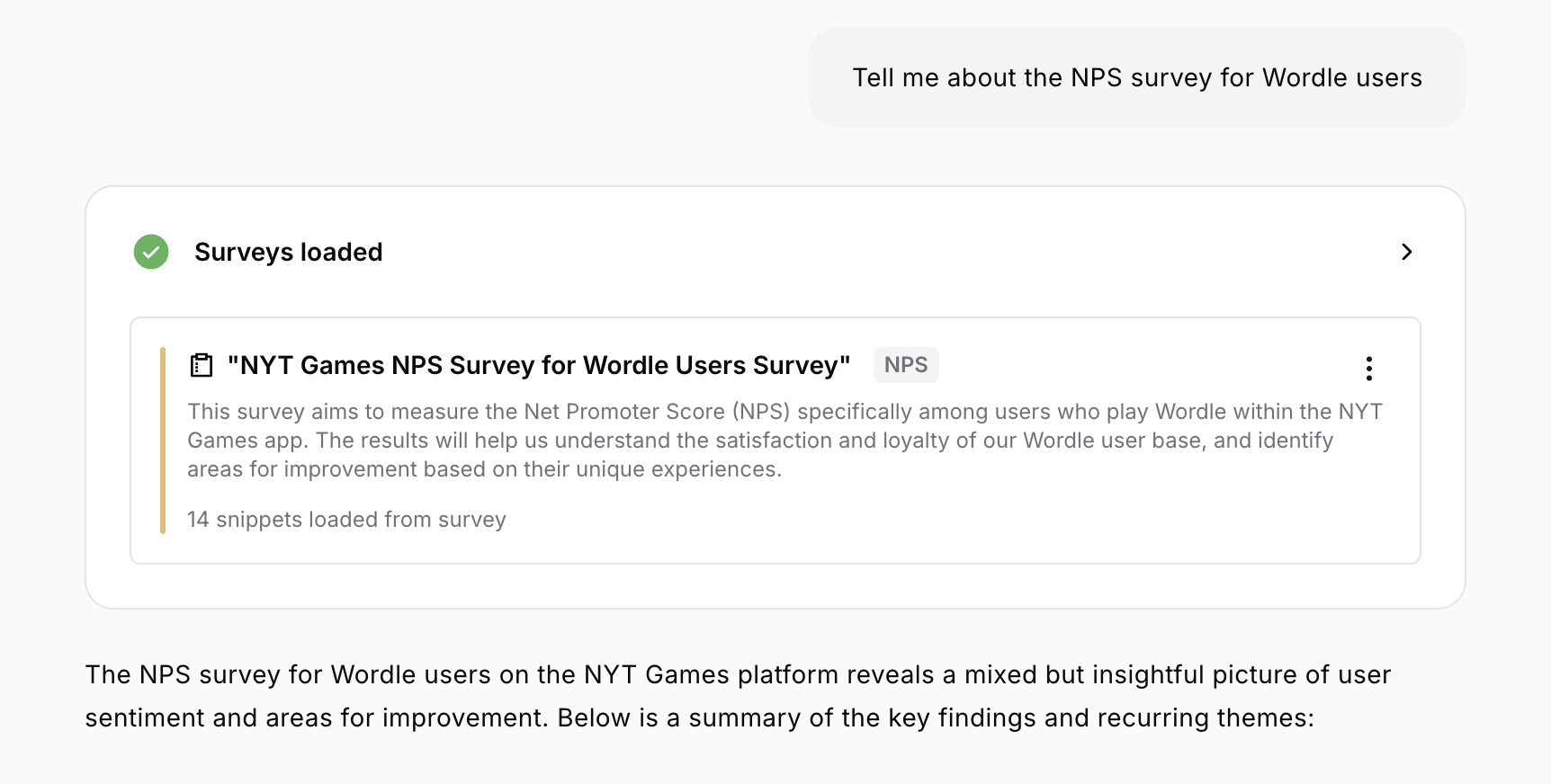
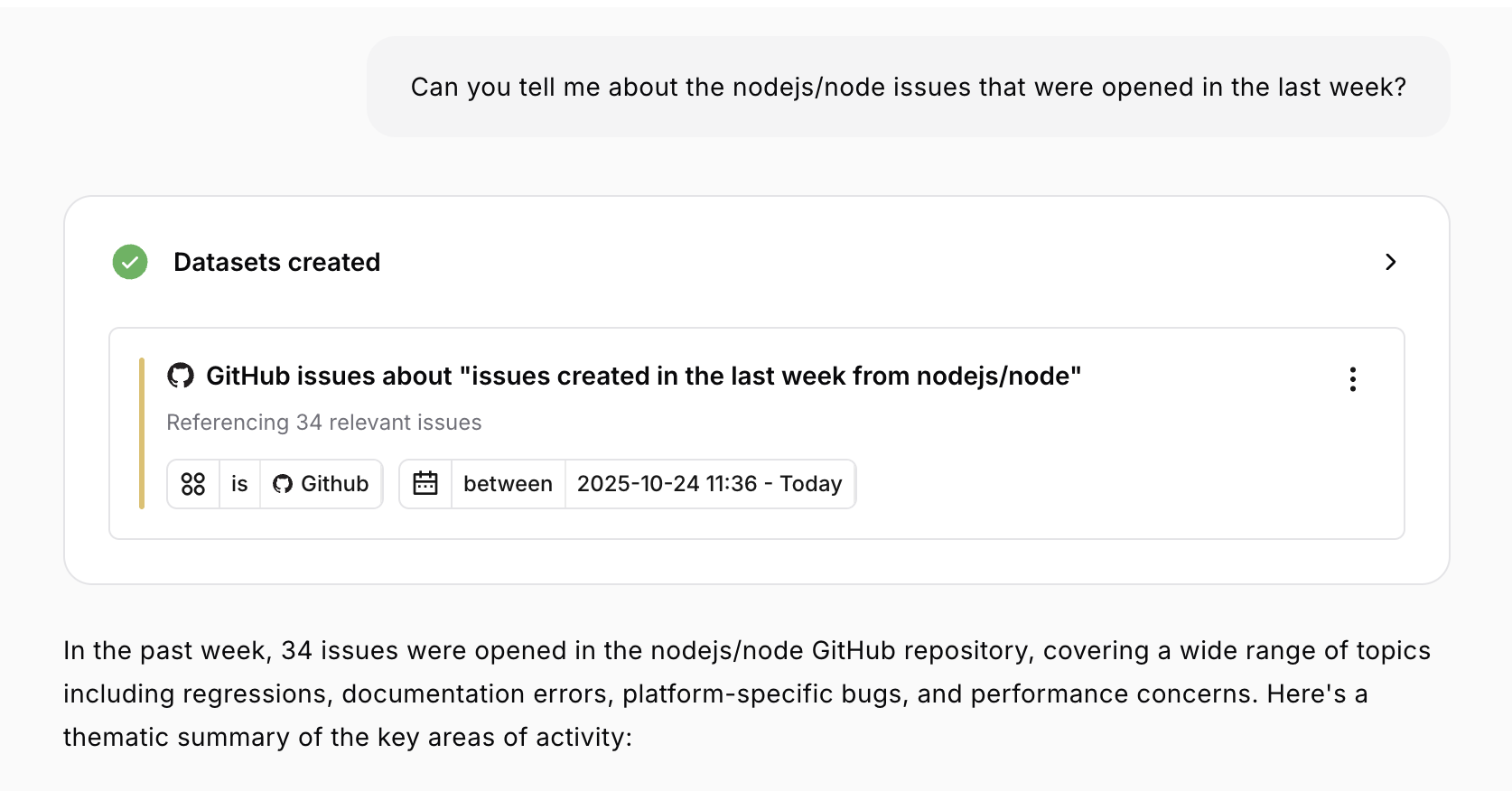
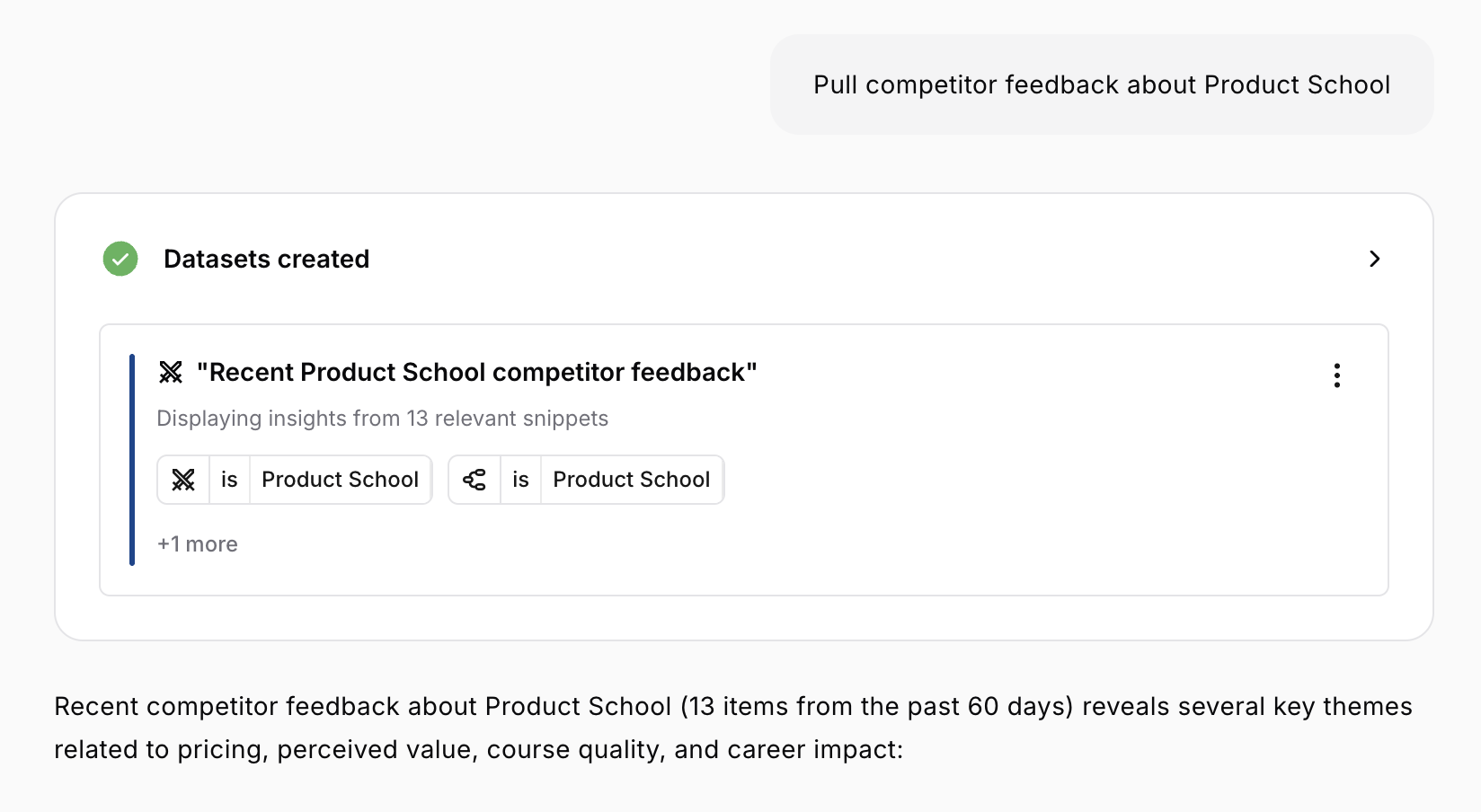
Working with Multiple Datasets
Many questions require Monty to create and compare multiple datasets.Comparison Queries
Segment Analysis
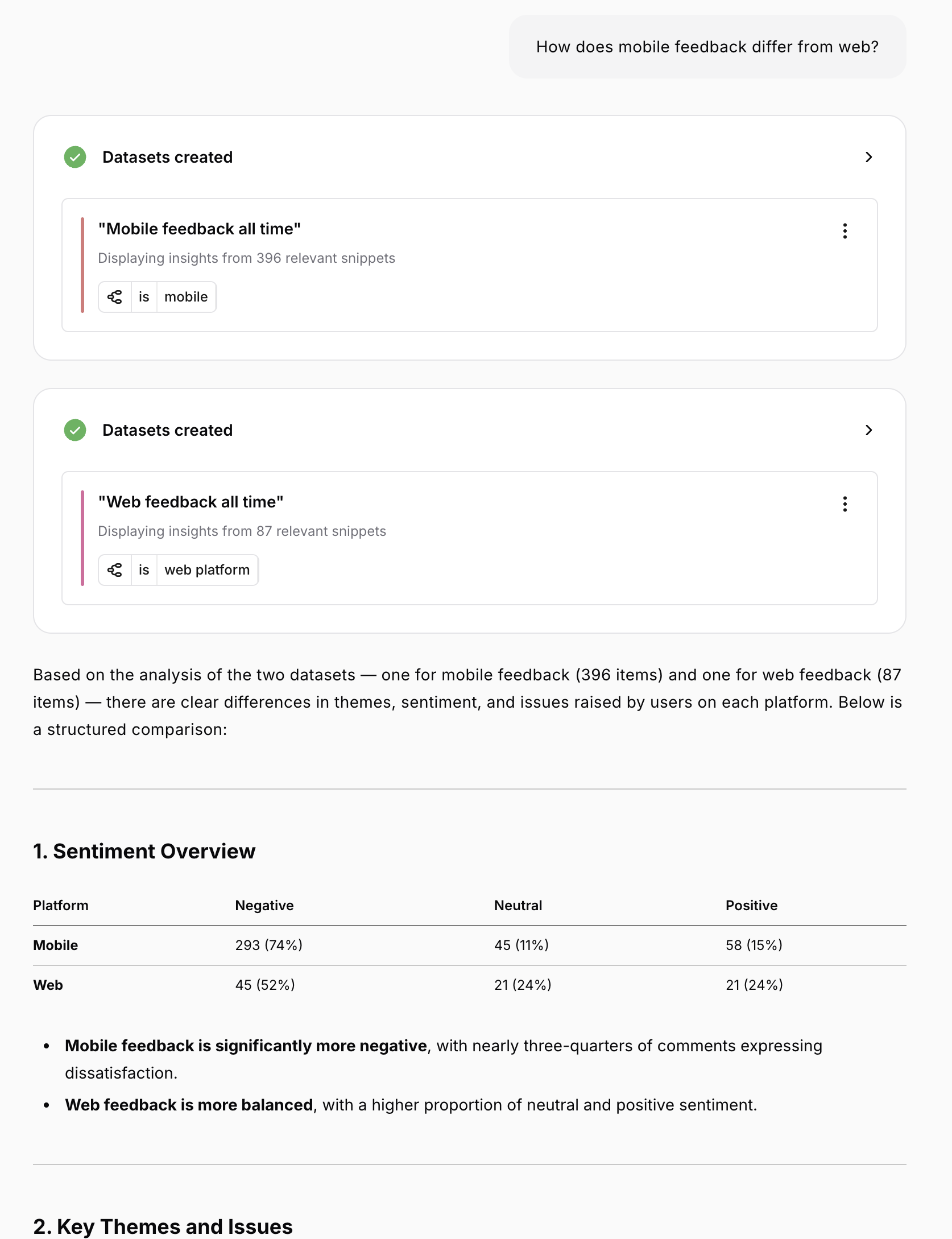
Complex Multi-Dataset Questions
Dataset Actions
Exporting Datasets
Export any dataset to CSV for external analysis:- Click the dataset menu (three dots)
- Select “Export to CSV”
- The exported CSV file will be saved to your browser’s downloads folder
- Feedback content/title
- Source and creation date
- Categories, projects, tags
- Sentiment scores
- Custom metadata
- Customer details (name, email, etc.)
Reusing Datasets
Within a conversation, Monty automatically reuses datasets when appropriate:Dataset Best Practices
Before diving into analysis, check that your dataset has sufficient data. While 500+ snippets enable robust insights and 100-500 provides good coverage, anything below 50 snippets might need broader filters. Dataset size directly affects the reliability of patterns Monty can identify. After Monty creates a dataset, take a moment to verify the filters match your intent. Check that date ranges are correct, the right sources are included, and categories align with what you asked for. If something looks off, rephrase your question to create a more accurate dataset. When comparing time periods, use equivalent ranges for fair comparison. Full months work better than rolling windows like “last 30 days” versus “previous 30 days,” which might include different day-of-week distributions that skew results. Remember that filters define what’s included and excluded. Filtering to “bugs” means you won’t see feature requests; filtering to “enterprise” excludes SMB feedback. Narrower isn’t always better—sometimes you need breadth to understand the full picture. For complex analysis beyond what Monty provides, export datasets to CSV and use Excel for pivot tables, your BI tools for custom visualizations, or statistical analysis software for deeper investigation.Dataset Limitations
Time Range Limits
Some dataset types have restrictions:- External datasets (GitHub/Jira): Maximum 60 days
- Web search: Shows recent results
- Feedback datasets: No hard limit
Data Availability
Datasets can only include what’s been ingested:- Feedback must be imported into the system
- Surveys must be created and run
- Integrations must be connected
- Historical data depends on when ingestion started
Performance Considerations
Very large datasets (10,000+ snippets) may:- Take longer to process
- Hit token limits in text responses
- Be sampled for analysis
Troubleshooting
When a dataset returns zero results, the most common culprits are time ranges that are too narrow, sources that haven’t imported data, or misspelled categories and tags. Monty will suggest adjustments when this happens. Try expanding your time range, removing some constraints, or checking that your filters reference correctly spelled categories. If you get fewer results than expected, broaden your scope by extending the time period, using less specific categories, making keywords more general, or including additional sources. Sometimes filters that seem right are actually excluding relevant data. When a dataset’s filters don’t match your intent, rephrase your question with more explicit constraints. Be specific about the time range, sources, categories, and any other filters you want applied. Sometimes a small change in phrasing helps Monty better understand what you’re looking for.Next: Surveys & Interviews →